这一篇教程,我们来了解如何爬取网页内容。
这里我们可以使用urllib这个模块。
基于前面的学习,对于模块中使用的一些方法、函数不再做具体说明,大家可以参考示例代码以及相应的注释进行理解。
另外,本篇内容需要读者具备一些HTML基础,可以自行查看一些相关资料,推荐学习W3school上的资料。
接下来,我们先来看一个案例。
例如,我发现了一个古诗文网,里面有一个唐诗三百首的页面。
http://so.gushiwen.org/gushi/tangshi.aspx
这个页面中包含了唐诗三百的目录,每一首诗都有一个单独的页面。
当我们在浏览器中查看这个页面的源代码,就能够看到目录所对应的源代码内容。
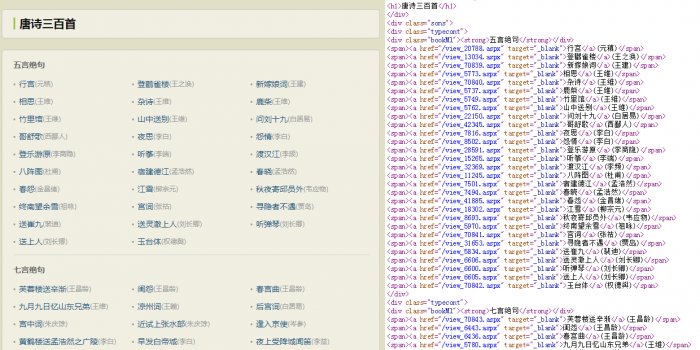
如果想爬取每一个古诗的页面,我们需要先获取到<a>标签中“href”属性的内容,然后连接“http://so.gushiwen.org”组成页面的绝对路径。
这里,我们可以创建一个生成器,能够生成所有古诗页面路径。
这个生成器我们需要包含两个步骤:获取目录页面的全部内容和获取<a>标签中的相对路径内容。
示例代码:(获取页面路径)
from urllib import request
import re
def get_urls():
pages = request.urlopen('http://so.gushiwen.org/gushi/tangshi.aspx') # 请求打开链接,获取到目录页面内容。
for line in pages: # 遍历页面内容的每一行HTML代码
rslt = re.search(r'<span><a href="(.+)" target="_blank">', line.decode())
# 通过正则表达式获取每首古诗页面的相对路径,保存到组。
if rslt: # 页面的HTML代码与正则表达式匹配
url = 'http://so.gushiwen.org' + rslt.group(1) # 取出组中保存的相对路径,连接为绝对路径。
yield url # 生成绝对路径
完成了每首古诗页面绝对路径的生成,接下来就可以进行古诗内容的抓取。

我们定义一个抓取古诗页面内容并写入文件的方法。
示例代码:(抓取写入文件)
def write_txt(urls, file): # 定义抓取内容并写入文件的方法,参数为绝对路径的生成器对象和打开的文件对象。
count = 0 # 创建计数变量
for url in urls: # 遍历所有的绝对路径
count += 1
file.write(str(count) + '\n') # 向文件中写入抓取的序号
html = request.urlopen(url) # 请求打开古诗页面的链接,获取页面内容。
for line in html: # 遍历页面内容的每一行HTML代码
title = re.search('<h1.+>(.+)</h1>', line.decode()) # 通过正则表达式获取古诗名称
source = re.search(r'.+source.+>(.+)</a>.+<a href=".+">(.+)</a>', line.decode())
# 通过正则表达式获取年代与作者
contson = re.search(r'([^</>\\w]+<br />[^</>\\w]+)', line.decode()) # 通过正则表达式获取古诗正文
if title: # 如果获取到标题
file.write(title.group(1) + '\n') # 向文件中写入古诗名称
if source: # 如果获取到古诗年代与作者
file.write(source.group(1) + ':' + source.group(2) + '\n') # 向文件中写入年代与作者
if contson: # 如果获取到古诗正文
file.write(contson.group(1).replace('<br />', '\n').strip('\n') + '\n\n')
# 向文件中写入古诗正文
break # 写入正文后跳出当前页面的读取
有了以上代码,我们就能够对目标页面进行抓取了。
示例代码:
if __name__ == '__main__':
with open('gushi.txt', 'w') as file: # 写入模式打开文件创建文件对象
urls = get_urls() # 创建生成器对象
write_txt(urls, file) # 调用抓取页面并写入文件的方法,将生成器对象和文件对象作为参数传入。
测试结果应该没有什么问题。
不过,上面抓取写入文件的代码中,正则表达式的可读性很差。
如果抓取一些结构更加复杂的网页,使用正则表达式也会变得非常困难。
那有没有更好的方法呢?
我们知道,在HTML中标签一般都是成对出现的,例如:
- 页面标签:开始标签<html>和结束标签</html>
- 主体标签:开始标签<body>和结束标签</body>
- 层的标签:开始标签<div>和结束标签</div>
- 段落标签:开始标签<p>和结束标签</p>
- 强调标签:开始标签<strong>和结束标签</strong>
当然,标签还有许多,也有一些自结束标签不是成对出现,例如图片标签。
我们一般抓取网页内容,实际上就是这些标签中的内容。
在Python中,提供了解析HTML的类HTMLParser,这个类存在于html.parser模块中。
HTMLParser类提供了一些方法,我们通过对这些方法进行重写,就能够满足抓取页面内容的需求。
这里,我们会用到其中的3个方法:
- handle_starttag:处理开始标签的方法
- handle_data:处理标签中数据的方法
- handle_endtag:处理开始标签的方法
handle_starttag方法会自动传入2个参数tag和attrs,我们能够通过这两个参数获取到当前所读取的标签名称与标签所包含的字段。
那么,就可以通过判断字段中是否包含指定的内容,来决定是否取出标签中的数据。
handle_data方法会自动传入1个data参数,这个参数中的内容就是当前所读取的标签中包含的内容,我们可以根据标签是否符合要求,来决定是否处理这个数据。
handle_starttag方法会传入1个tag参数,也就是结束标签的名称;我们可以在读取到指定结束标签时,进行结束数据读取的处理。
上面的解释不是很清晰,大家可以对照下方的示例代码进行理解,就能够非常清楚了。
在之前代码中,我们创建一个类继承HTMLParser类,并重写上述的3个方法。
示例代码:(创建解析器类)
from html.parser import HTMLParser
class MyHtmlParser(HTMLParser): # 创建一个类继承HTMLParser类
is_title = False # 定义添加古诗名称的开关变量
is_source = False # 定义添加古诗年代与作者的开关变量
is_contson = False # 定义添加古诗正文的开关变量
is_add = True # 定义是否添加当前页面数据的开关变量
def handle_starttag(self, tag, attrs): # 重写方法
attrs = dict(attrs) # 将参数转换为字典类型
if tag == 'h1': # 判断标签名称
self.is_title = True # 符合条件时开启添加古诗名称
if 'source' in attrs.values(): # 判断字典值中是否包含指定的值
self.is_source = True # 符合条件时开启添加古诗年代与作者
if 'contson' in attrs.values(): # 判断字典值中是否包含指定的值
self.is_contson = True # 符合条件时开启添加古诗正文
if 'tool' in attrs.values(): # 判断字典值中是否包含指定的值
self.is_add = False # 符合条件时关闭添加当前页面的数据
if tag == 'html': # 判断字典值中是否包含指定的值
self.is_add = True # 符合条件时开启添加当前页面的数据
self.content = [''] * 3 # 初始化保存某一页面内容的列表
def handle_endtag(self, tag): # 重写方法
if tag == 'h1': # 判断标签名称
self.is_title = False # 符合条件时关闭添加古诗名称
if tag == 'p': # 判断标签名称
self.is_source = False # 符合条件时关闭添加古诗年代与作者
if tag == 'div': # 判断标签名称
self.is_contson = False # 符合条件时关闭添加古诗正文
def handle_data(self, data): # 重写方法
data = data.replace('\n', '') # 替换掉数据中所有的换行符
if self.is_add: # 判断是否能够添加页面数据
if self.is_title: # 如果添加古诗名称为开启状态
self.content[0] = data # 添加古诗名称到页面内容列表
if self.is_source: # 如果添加古诗年代与作者为开启状态
self.content[1] = self.content[1] + data # 添加古诗年代与作者到页面内容列表
if self.is_contson: # 如果添加古诗正文为开启状态
self.content[2] = self.content[2] + data + '\n' # 添加古诗正文到页面内容列表
在上方代码中handle_starttag()方法负责判断当前所读取的标签是否抓取目标,然后打开相应的开关。
并且,初始化保存抓取内容的列表。
同时,因为页面中还有与其它推荐的古诗,我们在抓取完第一首古诗之后,就不能再抓取当前页面的内容;所以,这个抓取页面内容的开关也放在handle_starttag()方法中进行开启与关闭。
- 当读取到<html>标签(页面内容的开始)时开启内容抓取;
- 当读取的标签属性值包含“tool”时,关闭内容抓取。(大家可以观察页面源代码,在第一首古诗的下方会出现这个“tool”值。)
然后,handle_endtag()方法则是根据读取到的结束标签,关闭相应的开关。
最后,handle_data()方法根据各个开关的状态,对数据进行处理。如果读取页面数据的开关为打开状态,并且某项数据对应的开关也是打开状态,则将该项数据写入页面内容列表的指定位置。
完成了上面类的创建之后,接下来,我们需要修改一个抓取与写入文件的方法。
示例代码:
def write_txt(urls, file, pars): # 定义抓取并写入文件的方法,增加解析器对象的参数
count = 0 # 创建计数变量
for url in urls: # 遍历所有的绝对路径
html = request.urlopen(url).read().decode().replace('<strong>', '').replace('</strong>', '')
# 请求打开古诗页面的链接,获取页面内容。并且将页面中的<strong>标签替换为空值,因为它会影响格式。
pars.feed(html) # 通过解析器对象解析页面代码
count += 1
file.write(str(count) + '\n') # 向文件中写入抓取的序号
file.write(pars.content[0] + '\n') # 向文件中写入古诗名称
file.write(pars.content[1] + '\n') # 向文件中写入年代与作者
file.write(pars.content[2] + '\n') # 向文件中写入古诗正文
完成了方法的修改,接下来我们就能够对目标页面进行抓取了。
示例代码:
if __name__ == '__main__':
with open('gushi.txt', 'w') as file: # 写入模式打开文件创建文件对象
urls = get_urls() # 创建生成器对象
pars = MyHtmlParser() # 创建解析器对象
write_txt(urls, file, pars) # 调用抓取页面并写入文件的方法,将生成器对象、文件对象以及解析器对象作为参数传入。
pars.close() # 关闭解析器对象
本篇教程只是对页面内容抓取的入门内容,更深入的内容还需要查阅更多专业资料。
本节知识点:
1、使用urllib模块实现网页内容抓取;
2、使用HTMLParser类实现对HTML代码的解析。
本节英文单词与中文释义:
1、request:请求
2、title:标题
3、source:源
4、parser :解析器
5、tag:标签
6、data:数据
7、content:内容
8、feed:向…提供
转载请注明:魔力Python » Python3萌新入门笔记(52)