本系列文章参考国外编程高手鲁斯兰的博客文章《Let’s Build A Simple Interpreter》。
在这一篇文章中,我们主要学习以下内容:
- 作用域的作用是什么?如何在带有符号表的代码中实现?
- 什么是嵌套作用域?如何使用链式作用域符号表来实现嵌套作用域?
- 如何使用形式参数解析过程声明?如何在代码中表示过程符号?
- 当存在嵌套作用域时,如何扩展语义分析器以进行语义检查?
- 名称解析以及语义分析器如何在程序具有嵌套作用域时将名称解析为其声明?
- 如何构建作用域树?
- 如何编写一个源到源编译器(source-to-source compiler)?它和作用域有什么相关性?
一、作用域和作用域符号表
什么是作用域?
作用域是指名称在程序文本区域中的可用范围。
这个概念实际上学过《Python3萌新入门笔记》的同学都应该已经知道。
我们通过一段代码来加深理解。
program Main; var x, y: integer; begin x := x + y; end.
在Pascal程序中,PROGRAM关键字引入了一个新的作用域,通常叫做全局作用域。
因此上面的程序具有一个全局作用域,声明的变量“x”和“y”在整个程序范围内是可见和可访问的。
在上方的程序中,程序的文本区域以关键字PROGRAM开始,至关键字END和“.”结束。
在这个文本区域中可以使用变量“x”和变量“y”,因此这些变量(变量声明)的作用域是整个程序。
实际上,当我们提到变量的作用域时,是在说变量声明的作用域。
Pascal程序被称为词法作用域(lexically scoped),也称作静态作用域(statically scoped)。
因为我们可以查看源代码,甚至不执行程序,完全基于名称(引用)解析或引用哪些声明的文本规则来确定。
就像Pascal程序中通过词法关键词“PROGRAM”和“END”划分了作用域的文本范围。
那么,作用域有什么作用呢?
主要有以下几点作用:
- 每个作用域都创建一个独立的名称空间(命名空间),这意味着无法从作用域外部访问作用域内部声明的变量;
- 可以在不同的作用域中重复使用相同的名称,并且只需通过查看程序源代码,即可确切知道这个名称在程序中的不同位置时引用的哪一个声明。
- 在嵌套作用域中,可以重新声明与外部作用域中名称相同的变量,从而有效地屏蔽外部声明,这使我们可以控制对外部作用域中不同变量的访问。
除了全局作用域之外,Pascal还支持嵌套过程,并且每个过程声明都引入了一个新作用域,这意味着Pascal支持嵌套作用域。
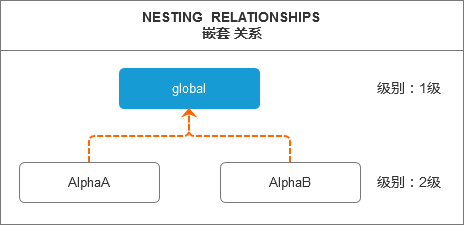
关于嵌套作用域,通过作用域级别可以很方便的表示嵌套关系。
并且,按名称引用作用域也很方便。
所以,在我们学习嵌套作用域时,会使用到它们。
在下图中包括一个示例程序,并在示例程序中标出了每个名称。
注意:下标用于表示同名变量所在作用域的级别,当前只有一个全局作用域,所以变量名称下标均为“1”。
通过这张图我们能够清楚地知道:
- 每个变量(符号)声明是什么级别;
- 变量名称引用了哪一个级别的声明。
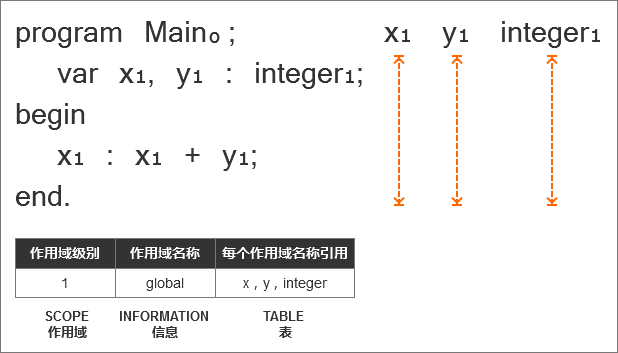
通过上图,我们能够知道以下信息:
- 程序有一个全局作用域,由关键字PROGRAM引入;
- 全局作用域的级别为1级;
- 变量(符号)“x”和“y”在级别为1的全局作用域中声明;
- 内置类型INTEGER也是在级别为1的全局作用域中声明;
- 程序名称“Main”有一个下标“0”,这个级别表示程序的名称不在全局作用域中,并且在其他一些外部作用域中,它的级别为0;
- 变量“x”和“y”的作用域是整个程序,如橙色垂直线所示;
- 作用域信息表显示了在程序中每个级别对应的作用域级别、作用域名称和作用域内声明的名称;这张表的目的是总结并直观地显示有关程序作用域的不同信息。
那么,我们如何在代码中实现作用域的概念?
我们需要一个作用域符号表(Scoped Symbol Table)。
我们现在只知道符号表,什么是作用域符号表呢?
作用域符号表基本上也是一个符号表,只是需要略作修改。
从这里开始,我们将使用“scope”来表示作用域的概念以及引用作用域符号表。
这是代码中作用域的实现。
即使在我们的代码中,作用域由ScopedSymbolTable类的实例表示,但是为了方便起见,我们将在整个代码中使用名为“scope”的变量。
因此,当我们的解释器代码中看到变量“scope”时,大家应该知道它实际上引用了作用域符号表。
我们将符号表类SymbolTable重命名为ScopedSymbolTable,并添加两个新的字段“scope_level”和“scope_name”,同时,我们也要修改“__str__()”方法,让它输出新的信息。
提示:和上一篇文章类似,我们将需要修改的代码(符号表和语义分析器)独立出来,在一个单独的python文件中编写。
示例代码:(scope01.py)
class ScopedSymbolTable:
def __init__(self, scope_name, scope_level):
self._symbols = OrderedDict()
self.scope_name = scope_name # 添加作用域名称
self.scope_level = scope_level # 添加作用域级别
self.__init_builtins()
...省略其它代码...
def __str__(self):
scope_header = '作用域符号表:' # 作用域符号表标题
lines = ['\n',scope_header, '=' * len(scope_header) * 2] # 添加输出内容格式
for header_name, header_value in (('作用域名称', self.scope_name), ('作用域级别', self.scope_level)): # 遍历作用域名称与级别
lines.append(f'{header_name:15}:{header_value}') # 添加作用域名称与级别到输出内容列表
symtab_header = '符号表中的内容:'
lines.extend(['\n',symtab_header, '-' * len(symtab_header) * 2])
lines.extend([f'{key:8}: {value}' for key, value in self._symbols.items()])
s = '\n'.join(lines)
return s
...省略其它代码...
接下来,我们更新语义分析器的代码,使用变量“scope”替换原有的“symbol_table”。
并且,从visit_VarDecl()方法中删除检查源程序中重复标识符的语义检查,以减少程序输出中的噪声。
示例代码:(scope01.py)
class SemanticAnalyzer(NodeVisitor):
def __init__(self):
self.scope = ScopedSymbolTable(scope_name='global',scope_level=1)
完成以上修改之后,我们使用下面的Pascal程序进行测试。
program Main; var x, y : integer; begin x := x + y; end.
测试结果如下:
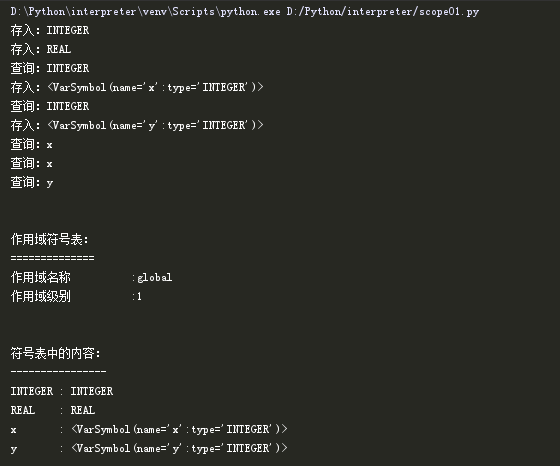
现在,我们已经了解了作用域的概念以及如何使用作用域符号表在代码中实现作用域。
下一步,我们学习嵌套作用域以及对作用域符号表的进行更多的修改,而不仅仅是添加两个简单字段。
二、带有形式参数的过程声明
我们先来看一个包含过程声明的Pascal程序。
program Main;
var x, y: real;
procedure Alpha(a : integer);
var y : integer;
begin
x := a + x + y;
end;
begin { Main }
end. { Main }
上方的Pascal程序代码和我们以往所见到的不同,在过程声明中包含了一个参数,我们还没有学习如何处理。
所以,在继续学习作用域的内容之前,我们先完成如何处理形式参数的学习。
提示:形式参数(Formal parameters)也称作正式参数,是在过程声明中显示的参数;参数(Arguments)也称作实际参数(Actual parameters),是在调用过程时传入的参数,可以是常量、变量、表达式、函数等。
下面是我们的解释器代码中需要增加和修改的内容。
1、添加参数的AST节点类。
参数和变量声明一样包含变量和类型。
示例代码:
class Param(AST):
def __init__(self, var_node, type_node):
self.var_node = var_node
self.type_node = type_node
2、修改过程声明的AST节点类
在过程声明的AST节点类构造函数中,需要增加对参数节点的获取。
注意参数可能是多个,所以参数节点是个列表。
示例代码:
class ProcedureDecl(AST):
def __init__(self, name, params, block_node):
self.name = name
self.params = params
self.block_node = block_node
3、更新声明的文法规则和代码
新的文法体现了过程声明中包含形式参数列表的子规则。
declarations : (VAR (variable_declaration SEMI)+)* | (PROCEDURE ID (LPAREN formal_parameter_list RPAREN)? SEMI block SEMI)* | empty
示例代码:
def declarations(self): # 修改创建声明节点的方法
declarations = []
while True:
if self.current_token.value_type == VAR:
self.eat(VAR)
while self.current_token.value_type == ID:
declarations.extend(self.variable_declaration())
self.eat(SEMI)
elif self.current_token.value_type == PROCEDURE:
self.eat(PROCEDURE)
procedure_name = self.current_token.value
self.eat(ID)
params = [] # 参数列表
if self.current_token.value_type == LPAREN: # 如果遇到左括号
self.eat(LPAREN) # 验证左括号
params = self.formal_parameter_list() # 获取参数列表
self.eat(RPAREN) # 验证右括号
self.eat(SEMI)
block_node = self.block()
procedure_decl = ProcedureDecl(procedure_name, params, block_node) # 创建包含参数的过程声明对象
declarations.append(procedure_decl)
self.eat(SEMI)
else:
break
return declarations
4、添加形式参数列表规则和方法
formal_parameter_list:formal_parameters | formal_parameters SEMI formal_parameter_list
示例代码:
def formal_parameter_list(self): # 添加创建参数列表节点的方法
if self.current_token.value_type != ID: # 如果没有参数
return [] # 返回空列表
param_nodes = self.formal_parameters() # 添加同类型参数节点到参数节点列表
while self.current_token.value_type == SEMI: # 当前记号是分号时还有更多参数
self.eat(SEMI) # 验证分号
param_nodes.extend(self.formal_parameters()) # 添加更多参数节点到参数节点列表
return param_nodes # 返回参数节点列表
5、添加形式参数的规则和方法
formal_parameters:ID(COMMA ID)* COLON type_spec
示例代码:
def formal_parameters(self): # 添加创建参数节点的方法
param_nodes = [] # 参数节点列表
param_tokens = [self.current_token] # 参数记号列表
self.eat(ID) # 验证第一个参数名称
while self.current_token.value_type == COMMA: # 当遇到逗号时
self.eat(COMMA) # 验证逗号
param_tokens.append(self.current_token) # 添加记号到参数记号列表
self.eat(ID) # 验证参数名称
self.eat(COLON) # 遍历结束验证冒号
type_node = self.type_spec() # 获取参数类型节点
for param_token in param_tokens: # 遍历参数记号列表
param_node = Param(Variable(param_token), type_node) # 通过参数记号创建参数节点
param_nodes.append(param_node) # 添加参数节点到参数节点列表
return param_nodes # 返回参数节点列表
通过添加上述方法和规则,我们的解析器已经能够解析像类似下方的过程声明:(为了简洁,此处没有显示声明过程的主体)
procedure Foo; procedure Foo(a : INTEGER); procedure Foo(a, b : INTEGER); procedure Foo(a, b : INTEGER; c : REAL);
下面是一个Pascal示例程序:
program Main;
var x, y: real;
procedure Alpha(a : integer);
var y : integer;
begin
x := a + x + y;
end;
begin { Main }
end. { Main }
根据我们当前完成的代码,这段程序的AST如下图所示:
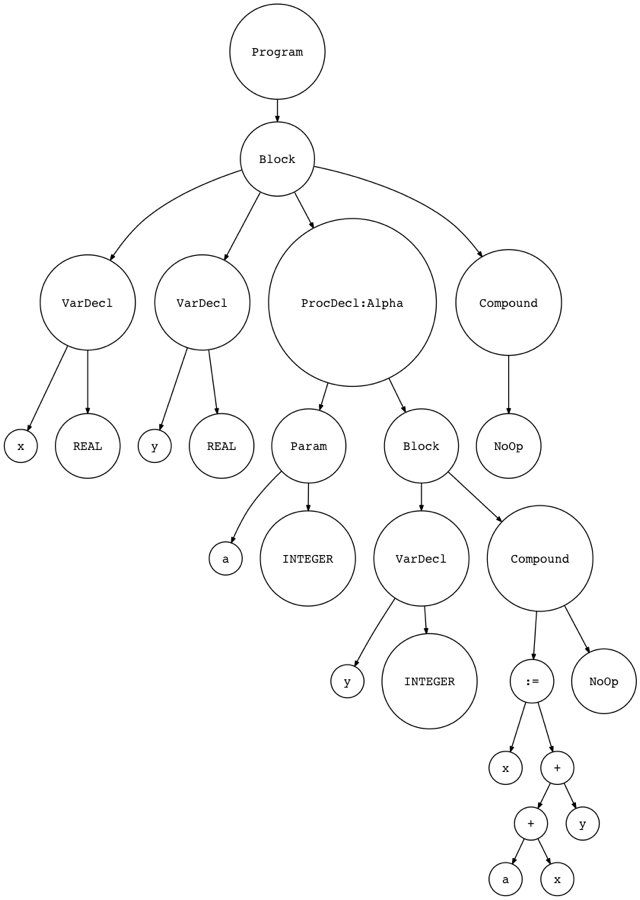
从上图中我们可以看到,ProcedureDecl节点将Param节点作为它的子节点。
三、过程符号
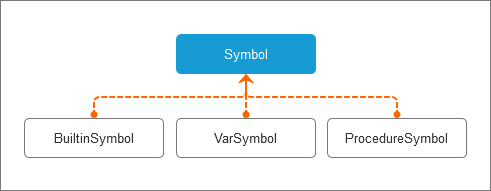
与变量声明和内置类型声明一样,过程也有一个单独的符号类别。
我们需要为过程符号创建一个单独的符号类。
示例代码:
class ProcedureSymbol(Symbol): # 添加过程符号类
def __init__(self, name, params=None): # 过程包含名称与形式参数信息
super().__init__(name)
self.params = params if params is not None else [] # 获取形式参数,如果未传入则为空列表。
def __str__(self):
return f"<{self.__class__.__name__}(name='{self.name}',parameters={self.params})>" # 过程的信息
__repr__ = __str__
过程符号有一个名称(过程的名称),它的类别是过程(类名中体现),类型是None,因为在Pascal的过程没有返回内容。
如上面的代码中所示,过程符号还包含关于过程声明的形式参数信息。
在添加了过程符号符号之后,当前符号的层次结构如下图所示:
四、嵌套作用域
完成了形式参数处理以及过程符号的学习,我们回到程序和嵌套作用域的内容上来。
回顾一下之前的Pascal程序代码。
program Main;
var x, y: real;
procedure Alpha(a : integer);
var y : integer;
begin
x := a + x + y;
end;
begin { Main }
end. { Main }
在上方代码中,通过声明一个新的过程(Alpha),我们引入了一个新的作用域,这个作用域嵌套在PROGRAM语句引入的全局作用域中。
我们再次通过一张图来了解一些信息。
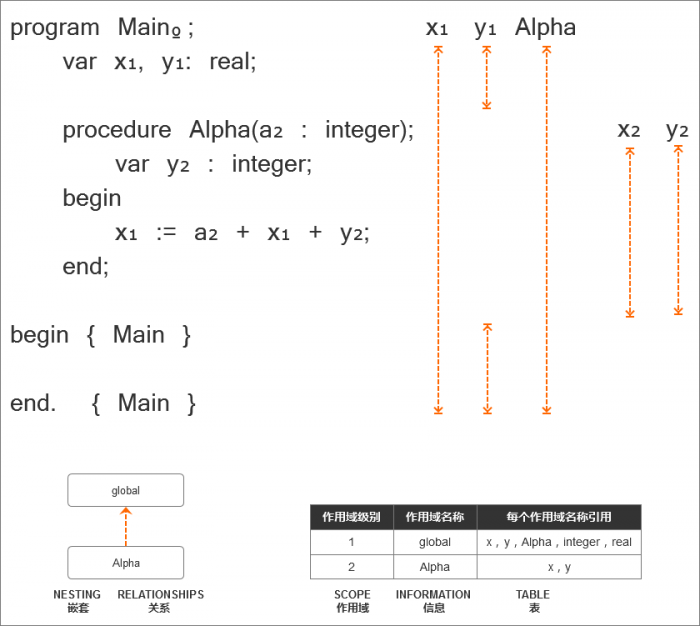
从上图中我们能够得到以下信息:
- 这个Pascal程序有两个范围级别:级别1和级别2;
- 嵌套关系显示了Alpha作用域嵌套在global作用域内,global作用域级别为1级,Alpha作用域级别为2级;
- 过程声明Alpha的作用域级别高于过程Alpha中所声明变量的级别,过程声明Alpha的作用域级别为1级,过程中变量“a”和“y”的作用域级别为2级;
- 过程Alpha中声明的变量“y”屏蔽了全局作用域中声明的变量“y”,我们可以看到变量“y₁”垂直线中的空缺以及变量“y₂”的作用域是过程Alpha的整体;
- 作用域信息表显示了不同的作用域级别、作用域名称以及在这些作用域中声明的相应名称;
- 在图片中,省略了整数和实数类型的作用域(范围信息表中除外),因为它们总是在全局作用域中声明。
接下来是实现的细节。
我们需要先了解关于变量和过程声明,然后再了解变量引用以及在嵌套作用域存在时名称解析的工作原理。
这里简化一下Pascal程序,去除变量引用的内容。
program Main;
var x, y: real;
procedure Alpha(a : integer);
var y : integer;
begin
end;
begin { Main }
end. { Main }
现在我们有两个作用域:全局作用域和过程Alpha引入的作用域。
按照我们的方法,我们现在应该有两个作用域符号表:一个用于全局作用域,一个用于Alpha作用域。
所以,我们需要扩展语义分析器,为每个作用域创建一个单独的作用域符号表。
那么,我们在语义分析器中的哪个位置创建作用域符号表呢?
PROGRAM和PROCEDURE关键字引入了新的作用域。
在AST中,相应的节点是Program和ProcedureDecl。
因此,我们将更新visit_Program()方法并添加visit_ProcedureDecl()方法以创建作用域符号表。
首先,我们更新visit_Program()方法。
示例代码:(scope02.py)
def __init__(self):
self.current_scope = None # 初始化保存符号表的变量(需要修改SemanticAnalyzer类代码中所有的self.scope为self.current_scope)
def visit_Program(self, node):
print('>>> 进入作用域:global') # 显示输出当前进入的作用域
global_scope = ScopedSymbolTable(scope_name='global', scope_level=1) # 创建作用域符号表
self.current_scope = global_scope # 将创建的符号表对象存入指定变量,对符号表的查询与插入将通过此变量进行。
self.visit(node.block)
print(global_scope) # 显示输出符号表信息
print('<<< 离开作用域:global') # 显示输出离开作用域的信息
然后,添加visit_ProcedureDecl()方法。
示例代码:(scope02.py)
def visit_ProcedureDecl(self, node):
proc_name = node.name # 获取过程节点名称
proc_symbol = ProcedureSymbol(proc_name) # 创建过程符号
self.current_scope.insert(proc_symbol) # 过程符号添加到当前作用域
print(f'>>> 进入作用域:{proc_name}') # 显示输出进入过程作用域
proc_scope = ScopedSymbolTable(scope_name=proc_name, scope_level=2) # 创建过程的作用域符号表
self.current_scope = proc_scope # 当前作用域设置为过程作用域
for param in node.params: # 遍历过程的形式参数列表
param_type = self.current_scope.lookup(param.type_node.name) # 获取参数类型
param_name = param.var_node.name # 获取参数名称
param_symbol = VarSymbol(param_name, param_type) # 创建参数符号
self.current_scope.insert(param_symbol) # 将参数符号添加到当前作用域
proc_symbol.params.append(param_symbol) # 为过程符号参数列表添加参数符号
self.visit(node.block_node) # 访问过程中的块节点
print(proc_scope) # 显示输出过程作用域符号表信息
print(f'<<< 离开作用域:{proc_name}') # 显示输出离开过程作用域
完成以上代码的修改,我们进行测试。
结果如下:

当我们执行程序时,内存中的作用域如下图所示,只是两个单独的作用域符号表。
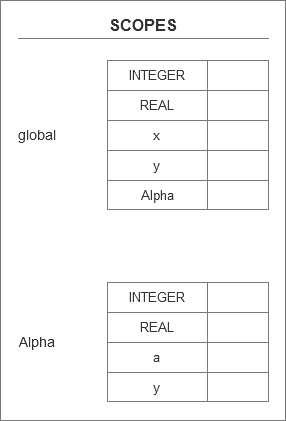
五、作用域树:链接作用域符号表
现在,每个作用域都有一个独立的作用域符号表,我们如何表示它们之间的嵌套关系呢?
我们需要把符号表链接到一起。
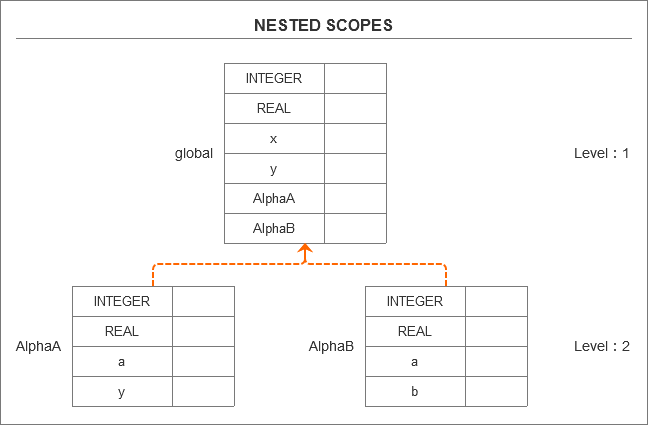
当我们创建链接来将作用域符号表链接在一起时,在某种程度上它会像一棵树(我们称之为作用域树)。
只是在这个树中,子级指向父级,如下图所示:
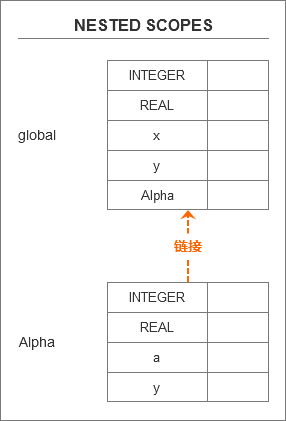
在上图中,我们能够看到Alpha作用域通过指向链接到了global作用域。
或者说,Alpha作用域指向了它的外围作用域(enclosing scope:封闭作用域),即global作用域。
也就意味着,Alpha作用域嵌套在global作用域内。
那么,我们如何才能实现作用域链接(scope chaining/linking)?
只需要以下两步:
- 更新ScopedSymbolTable类并添加一个变量“enclosing_scope”,这个变量将保存指向外围作用域的指针。(这就是在创建作用域之间的联系)
- 更新visit_Program()和visit_ProcedureDecl()方法,以使用新的ScopedSymbolTable 类,创建指向外围作用域的实际链接。
我们先来更新ScopedSymbolTable类并添加变量“enclosing_scope”(默认值为None)。
需要更新的是__init__()和__str__()方法。
更新__init__()方法是为了能够接受新的参数,更新__str__()方法是为了能够显示输出外围作用域的名称。
示例代码:
def __init__(self, scope_name, scope_level, enclosing_scope=None):
self._symbols = OrderedDict()
self.scope_name = scope_name
self.scope_level = scope_level
self.enclosing_scope = enclosing_scope # 添加外围作用域
self.__init_builtins()
def __str__(self):
scope_header = '作用域符号表:'
lines = ['\n', scope_header, '=' * len(scope_header) * 2]
for header_name, header_value in (
('作用域名称', self.scope_name),
('作用域级别', self.scope_level),
('外围作用域', self.enclosing_scope.scope_name if self.enclosing_scope else None) # 如果不存在外围作用域则为None
): # 遍历作用域名称和级别以及外围作用域
lines.append(f'{header_name:15}:{header_value}')
symtab_header = '符号表中的内容:'
lines.extend(['\n', symtab_header, '-' * len(symtab_header) * 2])
lines.extend([f'{key:8}: {value}' for key, value in self._symbols.items()])
s = '\n'.join(lines)
return s
接下来,我们修改语义分析器(SemanticAnalyzer类)中的方法。
先是visit_Program()方法。
示例代码:
def visit_Program(self, node):
print('>>> 进入作用域:global')
global_scope = ScopedSymbolTable(scope_name='global', scope_level=1,
enclosing_scope=self.current_scope) # 创建全局作用域符号表
self.current_scope = global_scope
self.visit(node.block)
print(global_scope)
self.current_scope = self.current_scope.enclosing_scope # 离开作用域时设置当前作用域为外围作用域
print('<<< 离开作用域:global')
这里需要注意的是:
- 在创建新的作用域时,我们将当前作用域“self.current_scope”作为enclosing_scope参数传递给新的作用域;
- 在完成新的作用域创建时,我们将新创建的作用域存入了当前作用域“self.current_scope”;
- 在离开Program节点之前,也就是离开作用域时,将当前作用域“self.current_scope”恢复为先前的值。在我们完成节点处理后恢复当前作用域“self.current_scope”的值很重要,否则当我们的程序中有两个以上的作用域时,作用域树的构造会被破坏。(想一想,如果程序中存在两个同级别的过程,当从一个过程离开进入另外一个过程时,作用域的变化应该是什么样的?)
然后,我们再修改visit_ProcedureDecl()方法。
示例代码:
def visit_ProcedureDecl(self, node):
proc_name = node.name
proc_symbol = ProcedureSymbol(proc_name)
self.current_scope.insert(proc_symbol)
print(f'>>> 进入作用域:{proc_name}')
proc_scope = ScopedSymbolTable(scope_name=proc_name, scope_level=self.current_scope.scope_level + 1,
enclosing_scope=self.current_scope) # 创建过程的作用域符号表
self.current_scope = proc_scope
for param in node.params:
param_type = self.current_scope.lookup(param.type_node.name)
param_name = param.var_node.name
param_symbol = VarSymbol(param_name, param_type)
self.current_scope.insert(param_symbol)
proc_symbol.params.append(param_symbol)
self.visit(node.block_node)
print(proc_scope)
self.current_scope = self.current_scope.enclosing_scope # 离开作用域时设置当前作用域为外围作用域
print(f'<<< 离开作用域:{proc_name}')
这段代码中需要注意的内容和前一段代码是一样的。
另外,还要注意创建作用域时,作用域的级别不再是硬编码,而是在当前作用域(即新创建作用域的外围作用域)级别上增加1。
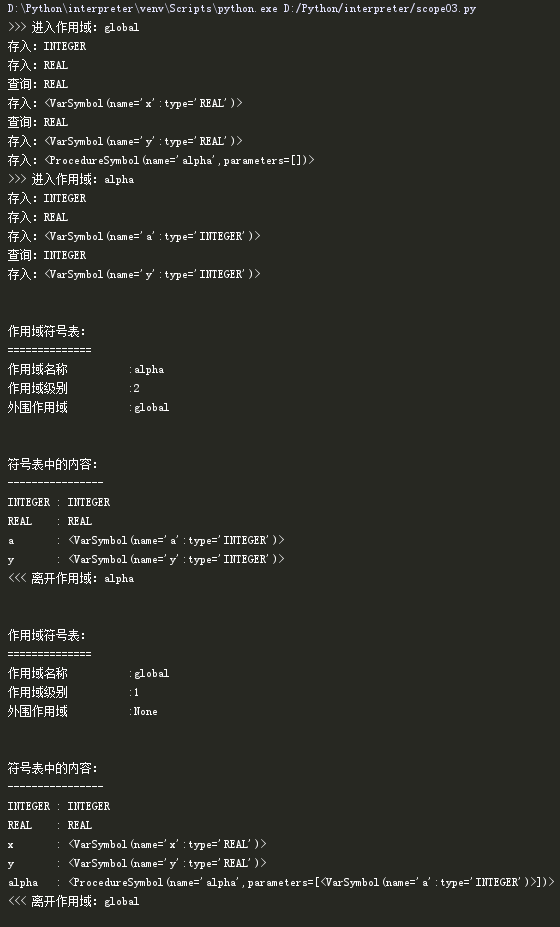
当完成以上修改之后,我们再次通过之前的Pascal程序代码进行测试。
测试结果如下:
我们再来通过一段Pascal程序进行测试。
program Main;
var x, y : real;
procedure AlphaA(a : integer);
var y : integer;
begin { AlphaA }
end; { AlphaA }
procedure AlphaB(a : integer);
var b : integer;
begin { AlphaB }
end; { AlphaB }
begin { Main }
end. { Main }
这里省略了测试结果,相信大家能够看到正确的结果。
在这段Pascal程序中,我们看到有两个同级别(2级)的过程AlphaA和AlphaB。
在我们的测试结果中,这两个过程的外围作用域都是global。
如果我们将visit_ProcedureDecl()方法中,离开作用域时的代码“self.current_scope = self.current_scope.enclosing_scope”注释掉,会是什么结果呢?

这时大家就能够看到过程AlphaA的作用域级别是2级,外围作用域时global。
但是,过程AlphaB的作用域级别是3级,外围作用域是AlphaA。
这就是为什么在我们完成节点处理后恢复当前作用域“self.current_scope”的值。
所以,要正确构建作用域树,我们需要遵循一个非常简单的过程:
- 当我们进入一个Program或ProcedureDecl节点,此时创建了一个新的作用域,并将它分配给当前作用域变量“self.current_scope”。
- 当我们离开一个Program或ProcedureDecl节点,需要恢复当前作用域变量“self.current_scope”的值。
我们可以将变量“self.current_scope”视为堆栈指针,将作用域树视为堆栈集合:
- 当我们访问Program或ProcedureDecl节点时,会向堆栈上加入一个新的作用域,并将堆栈指针“self.current_scope”调整为指向堆栈顶部,该堆栈现在是最近加入的作用域。
- 当我们即将离开节点时,将最近加入的作用域从堆栈中弹出,并且调整堆栈指针指向堆栈上的前一个作用域,也就是堆栈的新顶部。
建议大家自行了解一下关于堆栈的概念。
当我们正确的完成了代码,此时的作用域树如下图所示:
正如上面提到的,我们可以将上面的作用域树视为作用域堆栈的集合。
六、嵌套作用域和名称解析
我们先来看一段Pascal程序代码:
program Main;
var x, y: real;
procedure Alpha(a : integer);
var y : integer;
begin
x := a + x + y;
end;
begin { Main }
end. { Main }
在上方代码中,新增了一条赋值语句:
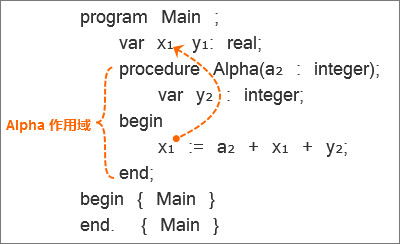
x₁ := a₂ + x₁ + y₂;
我们看到变量“x”引用的声明作用域级别为1级,变量“a”和变量“y”引用的声明作用域级别为2级。
那么,引用是如何工作的呢?
在名称解析方面,像Pascal这样的词法(静态)作用域遵循紧密嵌套作用域(the most closely nested scope)规则。
也就意味着,每一个作用域中,名称指向词法上最相近的声明。
对于上述赋值语句,我们查看每个变量的引用,从而得出规则在实践中是如何工作的。
1、因为我们的语法分析器先访问赋值语句的右侧,所以我们从表达式“a + x + y”开始。我们在词法最接近的作用域(Alpha作用域)内对变量“a”的声明进行搜索,此时能够在程序声明的形式参数中找到变量“a”的声明。

2、然后,是表达式中第2个变量“x”,因为在最近的Alpha作用域中,找不到变量“x”的声明,所以将搜索范围扩大到向外围作用域(global作用域)。在global作用域中找到了变量“x”的声明。

3、接下来,是表达式中最后一个变量“y”,在与这个变量最接近的作用域(Alpha作用域)中,我们能够找到这个变量的声明,在这个声明中变量“y”的类型是一个整数。大家试想一下,如果在Alpha作用域中没有变量“y”的声明会怎样?答案很简单,它会扩大搜索范围到外围作用域(global作用域),找到变量的声明。此时变量“y”的类型会是一个实数。

4、最后,我们来看赋值语句的左侧。这里也有个变量“x”,同样,它的声明最终会在global作用域中找到。
当我们了解了以上内容,当前面临的问题是:如何实现在当前作用域中进行查找后,再进入外围作用域进行查找,直到找到我们所查找的符号?
还有,如果已经查找到作用域树的顶部,没有更多的作用域时如何处理?
我们需要扩展ScopedSymbolTable类中的查找方法,实现在作用域树中的链式查找。
示例代码:(scope04-1.py)
def lookup(self, name):
print(f'查询:{name}(作用域:{self.scope_name})')
symbol = self._symbols.get(name) # 在当前作用域查找符号
if symbol: # 如果找到符号
return symbol # 返回符号
if self.enclosing_scope: # 如果当前作用域没有找到符号并且存在外围作用域
return self.enclosing_scope.lookup(name) # 递归方式在外围作用域进行查找
完成这段代码之后,我们还要修改一下初始化内置类型的代码。
我们在ScopedSymbolTable类的构造方法中删除初始化内置类型的语句,并在语义分析器的visit_Program()方法中添加初始化内置类型的语句。
示例代码:
def visit_Program(self, node):
print('>>> 进入作用域:global')
global_scope = ScopedSymbolTable(scope_name='global', scope_level=1,
enclosing_scope=self.current_scope)
global_scope._init_builtins() # 初始化内置类型
...省略其它代码...
到这里,我们就可以使用前面的Pascal程序进行测试了。
测试结果如下:
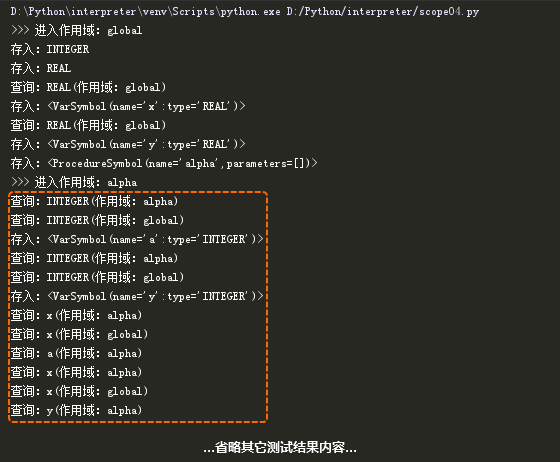
在上图中,我们能够看到:
- 在处理形式参数“a”以及声明的变量“y”的类型时,会先在当前作用域(Alpha作用域)中查找,未找到时会到外围作用域(global作用域)中查找。
- 在处理赋值语句时,变量“a”和变量“y”都在当前作用域(Alpha作用域)中找到,而变量“x”则是在外围作用域(global作用域)中找到。
我们再来做个测试。
例如,在下方代码中有一个未声明的变量会是什么结果?
program Main;
var x, y: real;
procedure Alpha(a : integer);
var y : integer;
begin
x := b + x + y; {这里是错误代码, 变量“b”未声明。 }
end;
begin { Main }
end. { Main }
测试结果如下:(scope04-2.py)
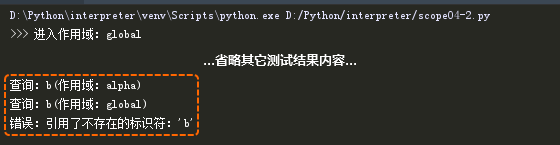
大家能够看到,在测试结果中,先在Alpha作用域中查询了变量“b”的声明;当没有查询到时,又进入了global作用域中查询;仍然没有查询到时,抛出了异常,显示输出错误信息。
七、源到源编译器
现在开始,我们接触一个全新的内容:编写一个源到源编译器(source-to-source compiler)。
首先,我们先来了解一下源到源编译器的概念。
出于本文的目的,让我们将源到源编译器定义为编译器,能够将某种源语言的程序转换为相同(或几乎相同)源语言的程序。
因此,如果我们编写一个转换程序,将Pascal程序作为输入的源代码并输出Pascal程序源代码(可能已修改或增强),则这个转换程序称为源到源编译器。
这是一个学习源到源编译器很好的例子。
我们把Pascal程序作为输入,并输出一个Pascal程序,不过,输出的Pascal程序中,每个名称都用数字下标标示它的作用域级别,并且每个变量引用也有一个类型指示符。
下面是我们要输入的Pascal程序。
program Main;
var x, y: real;
procedure Alpha(a : integer);
var y : integer;
begin
x := a + x + y;
end;
begin { Main }
end. { Main }
然后,是我们通过转换器或者说源到源编译器输出的Pascal程序。
program Main0;
var x1 : REAL;
var y1 : REAL;
procedure Alpha1(a2 : INTEGER);
var y2 : INTEGER;
begin
<x1:REAL> := <a2:INTEGER> + <x1:REAL> + <y2:INTEGER>;
end; {END OF Alpha}
begin
end. {END OF Main}
接下来,我们了解一下转换的规则:
- 每个声明都单独为一行。因此,如果我们输入的Pascal程序中有多个声明,则编译后输出的每个声明都在单独的一行。我们可以看到,在上面输入的Pascal程序中,变量声明“var x,y:real;”在被输出时被转换成了多行。
- 每个名称带有数字下标,这个数字下标是对应该名称声明的作用域级别。
- 每个变量输出的格式:<变量名称与下标:类型>。
- 编译器还以{ END OF …}的形式在每个块的末尾添加注释,其中省略号将替换为程序名称或过程名称。
从上面输出的Pascal程序代码可以看出,源到源编译器随我们理解名称解析非常有用,特别是当程序具有嵌套作用域时,因为编译器输出的新Pascal程序让我们我们能够更直观的看到某个变量引用所解析的声明和作用域。
在了解符号、嵌套作用域和名称解析时,这是很好的帮助。
那么,如何实现这样的源到源编译器呢?
实际上之前我们所编写的代码已经涵盖了所有必要的部分。
我们现在需要做的就是扩展我们的语义分析器以完成新程序的输出,染它能够返回某些AST 节点改进并生成的字符串。
我们将语义分析器类重命名为SourceToSourceCompiler,并添加代码。
以下是源到源编译器的完整代码。
示例代码:(s2s_compiler.py)
from collections import OrderedDict
from interpreter14 import Lexer, Parser, NodeVisitor, BuiltinTypeSymbol, VarSymbol, ProcedureSymbol
class SourceToSourceCompiler(NodeVisitor): # 修改语义分析器为源到源编译器
def __init__(self):
self.current_scope = None
self.output = None # 添加输出内容变量
def visit_Program(self, node):
result_str = f'program {node.name}0\n' # 添加程序声明到输出内容
global_scope = ScopedSymbolTable(scope_name='global', scope_level=1,
enclosing_scope=self.current_scope)
global_scope._init_builtins()
self.current_scope = global_scope
result_str += self.visit(node.block) # 添加块信息到输出内容
result_str += (f'.{{END OF {node.name}}}') # 添加程序结束信息到输出内容
self.output = result_str # 添加输出内容到输出内容变量
self.current_scope = self.current_scope.enclosing_scope
def visit_ProcedureDecl(self, node):
proc_name = node.name
proc_symbol = ProcedureSymbol(proc_name)
self.current_scope.insert(proc_symbol)
result_str = f'procedure {proc_name}{self.current_scope.scope_level}' # 添加过程声明到输出内容
proc_scope = ScopedSymbolTable(scope_name=proc_name, scope_level=self.current_scope.scope_level + 1,
enclosing_scope=self.current_scope)
self.current_scope = proc_scope
if node.params: # 如果包含形式参数
result_str += '(' # 添加左括号到输出内容
formal_params = [] # 形参列表
for param in node.params:
param_type = self.current_scope.lookup(param.type_node.name)
param_name = param.var_node.name
param_symbol = VarSymbol(param_name, param_type)
self.current_scope.insert(param_symbol)
proc_symbol.params.append(param_symbol)
formal_params.append(f'{param_name}{self.current_scope.scope_level}:{param_type}') # 参数信息添加到形参列表
result_str += ';'.join(formal_params) # 形参以分号分隔添加到输出内容
if node.params: # 如果包含形式参数
result_str += ')' # 添加右括号到输出内容
result_str += ';\n' # 添加分号和换行符到输出内容
result_str += self.visit(node.block_node) # 添加过程中的块信息到输出内容
result_str += f';{{END OF {proc_name}}}' # 添加过程结束信息到输出内容
result_str = '\n'.join(' ' + line for line in result_str.splitlines()) # 过程代码每行添加3个空格
self.current_scope = self.current_scope.enclosing_scope
return result_str # 返回输出内容
def visit_Block(self, node):
results = [] # 输出内容列表
for declaration in node.declarations:
result = self.visit(declaration) # 获取声明信息
results.append(result) # 添加声明信息到输出内容
results.append('\nbegin') # 添加开始标记到输出内容
result = self.visit(node.compound_statement) # 获取复合语句信息
result = ' ' + result # 语句前添加3个空格
results.append(result) # 添加复合语句到输出内容
results.append('end') # 添加结束标记到输出内容
return '\n'.join(results) # 返回输出内容
def visit_VarDecl(self, node):
symbol_type = node.type_node.name
self.current_scope.lookup(symbol_type)
var_name = node.var_node.name
var_symbol = VarSymbol(var_name, symbol_type)
self.current_scope.insert(var_symbol)
return f' var {var_name}{self.current_scope.scope_level} : {symbol_type}' # 返回变量声明信息
def visit_Compound(self, node):
results = [] # 输出内容列表
for child in node.children:
result = self.visit(child) # 获取子节点信息
if result is None:
continue
results.append(result) # 添加子节点信息到输出内容列表
return '\n'.join(results) # 返回输出内容
def visit_NoOperator(self, node):
pass
def visit_Variable(self, node):
var_name = node.name
var_symbol = self.current_scope.lookup(var_name)
if var_symbol is None:
raise NameError(f'错误:引用了不存在的标识符:{repr(var_name)}')
return f'<{var_name}{var_symbol.scope.scope_level}:{var_symbol.symbol_type}>' # 返回变量信息内容
def visit_BinaryOperator(self, node):
left = self.visit(node.left) # 获取表达式左侧内容
right = self.visit(node.right) # 获取表达式右侧内容
return f'{left} {node.operator.value} {right}' # 返回表达式内容
def visit_Assign(self, node):
left = self.visit(node.left) # 获取表达式左侧内容
right = self.visit(node.right) # 获取表达式右侧内容
return f'{left} := {right}' # 返回表达式内容
class ScopedSymbolTable:
def __init__(self, scope_name, scope_level, enclosing_scope=None):
self._symbols = OrderedDict()
self.scope_name = scope_name
self.scope_level = scope_level
self.enclosing_scope = enclosing_scope
def _init_builtins(self):
self.insert(BuiltinTypeSymbol('INTEGER'))
self.insert(BuiltinTypeSymbol('REAL'))
def __str__(self):
scope_header = '作用域符号表:'
lines = ['\n', scope_header, '=' * len(scope_header) * 2]
for header_name, header_value in (
('作用域名称', self.scope_name),
('作用域级别', self.scope_level),
('外围作用域', self.enclosing_scope.scope_name if self.enclosing_scope else None)
):
lines.append(f'{header_name:15}:{header_value}')
symtab_header = '符号表中的内容:'
lines.extend(['\n', symtab_header, '-' * len(symtab_header) * 2])
lines.extend([f'{key:8}: {value}' for key, value in self._symbols.items()])
s = '\n'.join(lines)
return s
__repr__ = __str__
def insert(self, symbol):
self._symbols[symbol.name] = symbol
symbol.scope = self # 插入符号时添加符号作用域字段并赋值为当前符号表对象(即作用域)
def lookup(self, name):
symbol = self._symbols.get(name)
if symbol:
return symbol
if self.enclosing_scope:
return self.enclosing_scope.lookup(name)
if __name__ == '__main__':
import sys
text = open(sys.argv[1], 'r').read()
lexer = Lexer(text)
parser = Parser(lexer)
tree = parser.parser()
compiler = SourceToSourceCompiler()
compiler.visit(tree)
print(compiler.output)
下面是一个更大的Pascal程序。
program Main; var b, x, y : real; var z : integer; procedure AlphaA(a : integer); var b : integer; procedure Beta(c : integer); var y : integer; procedure Gamma(c : integer); var x : integer; begin { Gamma } x := a + b + c + x + y + z; end; { Gamma } begin { Beta } end; { Beta } begin { AlphaA } end; { AlphaA } procedure AlphaB(a : integer); var c : real; begin { AlphaB } c := a + b; end; { AlphaB } begin { Main } end. { Main }
大家可以将这个Pascal程序以绘制垂直线的方式表示声明的作用域,并完成嵌套关系图和作用域信息表。
之后,再使用我们的编译器输出结果进行对照。
在这个过程中大家需要了解到以下内容:
- 作用域(垂直线)中的空缺部分表示在嵌套作用域中重新声明了同名变量。
- AlphaA和AlphaB是在global作用域内声明。
- AlphaA和AlphaB的声明引入新的作用域。
- 作用域如何嵌套在彼此之间,以及它们的嵌套关系。
- 为什么不同的名称(包括赋值语句中的变量引用)按照它们的方式t添加数字下标。或者说,链式作用域符号表的名称解析和具体查找方法是如何工作的。
最后,还要补充一点。
在之前的文章中,我们删除了对重复标识符(名称)的语义检查,在这里,我们再把它添加回来。
不过,需要注意的是,在不同作用域中是允许出现相同名称标识符(名称)的,只有在同一个作用域中不能够出现相同的标识符(名称)。
所以,我们我们仅在当前作用域进行标识符(名称)的查找。
示例代码:(scope05.py)
def visit_VarDecl(self, node): # 修改访问变量声明的方法
symbol_type = node.type_node.name
self.current_scope.lookup(symbol_type)
var_name = node.var_node.name
var_symbol = VarSymbol(var_name, symbol_type)
if self.current_scope.lookup(var_name, current_scope_only=True) is not None: # 查询变量名称,如果存在变量信息
raise Exception(f'错误:发现重复的标识符:{var_name}') # 抛出异常
self.current_scope.insert(var_symbol)
def lookup(self, name, current_scope_only=False): # 修改符号表类的查找方法
symbol = self._symbols.get(name)
if symbol:
return symbol
if current_scope_only: # 如果仅查找当前作用域,在没有查到符号时返回None。
return None
if self.enclosing_scope:
return self.enclosing_scope.lookup(name)
完成以上修改之后,我们可以通过一段错误程序进行测试。
program Main;
var x, y: real;
procedure Alpha(a : integer);
var y : integer;
var a : real; { ERROR here! }
begin
x := a + x + y;
end;
begin { Main }
end. { Main }
测试结果的最后一句内容是“错误:发现重复的标识符:a”。
后记:
到这里,关于解释器与编译器的内容就结束了。
当然,如果我们的外国高手鲁斯兰还会继续更新这个系列最后3篇文章的话,我依然会继续进行翻译整理。
当前这篇文章,我耗时4天(是整天而不是业余时间)才完成,这是我第一次写到这么长的内容。
不过,我觉得非常有意义。
这个系列文章,整个过程走过来,接触到很多新的知识,能让新手不论是编程的思想、概念、技巧、层次等方面都会有提高。
所以,非常推荐大家能够从头到尾的学习一遍由魔力Python为大家翻译整理的《一起来写个简单的解释器》系列文章。
不要在意当前这个系列有缺少的3篇文章,现有的14篇文章,以及能够让我们学习到很多有用的知识。
最后,还请大家多多转发本站(opython.com)原创发布的各类教程,让更多初学者从中受益。
我也会一如既往的,继续为大家献上更多通俗易懂的Python相关原创教程。
项目源代码下载:【点此下载】
转载请注明:魔力Python » 一起来写个简单的解释器(14)