本系列文章参考国外编程高手鲁斯兰的博客文章《Let’s Build A Simple Interpreter》。
这篇文章,我们真正开始实现对Pascal语言所编写的程序代码进行解释的功能。
相对于之前的命令行解释器,这是一个相当大的跳跃。
不过,不用担心,我会尽量让大家和我一起搞懂它。
本篇文章具体任务如下:
- 如何解析和解释Pascal程序的定义。
- 如何解析和解释复合语句。
- 如何解析和解释赋值语句,包括变量。
- 如何在符号表存储和查找变量。
先来看一下我们要解释的程序代码:
BEGIN
BEGIN
number := 2;
a := number;
b := 10 * a + 10 * number / 4;
c := a - - b;
END;
x := 11;
END.
这些代码,相信大家都能够轻易读懂。
这里我们记住上方代码内容的一些关键点:
- Pascal程序代码以点“.”作为结束符号。
- 结束符号之前的内容是复合语句:BEGIN…END。
- 复合语句中可以包含一条或多条语句,也能够嵌套复合语句。
- 除了程序结束语句,每条语句都以分号“;”结尾。
- 赋值语句由变量名称、赋值符“:=”以及右侧的表达式组成。
- BEGIN和END是保留字。
根据总结出的关键点,我们第一步要做的是完善文法内容。
首先,我们能够看到,新增了几个终结符。
- BEGIN:复合语句开始标记
- END:复合语句结束标记
- ASSIGN:赋值符“:=”
- SEMI:语句结束符“;”
- DOT:程序结束符“.”
- ID:变量的名称
然后,我们再来看文法。
1、程序包含复合语句和结束符号“.”。
program : compound_statement DOT
2、复合语句包含复合语句和语句列表。
compound_statement : BEGIN statement_list END
3、语句列表包含语句或分号分隔的语句与语句列表。
statement_list : statement | statement SEMI statement_list
4、语句包含复合语句、赋值语句或空语句。
statement : compound_statement | assignment_statement | empty
5、赋值语句包含变量、赋值符和表达式。
assignment_statement : variable ASSIGN expr
6、变量包含名称。
variable : ID
7、空语句没有任何内容。
empty :
8、因子增加了变量
factor : PLUS factor | MINUS factor | INTEGER | LPAREN expr RPAREN | variable
提示:在“compound_statement ”规则中,没有使用星号来表示零个或多个重复,而是明确地指定了“statement_list ”规则。这是表示“零或多”操作的另一种方法。另外,还将“(PLUS | MINUS) factor”分为了两个单独的规则。
理清了文法,接下来我们开始程序的功能的增加与修改。
一、增加常量
对于新增加的终结符,我们要声明新的常量。
并且,保留字也要以字典的形式声明一个常量。
示例代码:
ASSIGN, SEMI, DOT, BEGIN, END, ID = 'ASSIGN', 'SEMI', 'DOT', 'BEGIN', 'END', 'ID' # 增加新的终结符常量
RESERVED_KEYWORDS = { # 保留字字典
'BEGIN': Token(BEGIN, 'BEGIN'),
'END': Token(END, 'END')
}
二、添加词法分析器(Lexer)中的方法
1、查看下一字符的方法。
为了区别开头相同的不同记号(例如“:”和“:=”),我们需要在遇到特定开头的记号时查看下一字符,并且不能让位置增加。
解决方案是添加一个peek()方法。
示例代码:
def peek(self):
pos = self.position + 1 # 获取下一个位置
if pos >= len(self.text): # 如果超出文本末端
return None # 返回None
else: # 否则
return self.text[pos] # 返回下一位置字符
2、添加处理保留字和变量的方法。
Pascal中保留字和变量都是标识符,我们需要能够区分。
当词法分析器(Lexer)消耗一系列字母数字字符产生字符序列时,如果字符序列是保留字(这里只有BEGIN和END)就返回保留字的记号,否则返回一个以字符序列为值的ID记号。
示例代码:
def _id(self): # 获取保留字或赋值名称记号的方法
result = ''
while self.current_char is not None and self.current_char.isalnum(): # 如果当前字符是字母数字
result += self.current_char # 连接字符
self.advance() # 提取下一个字符
token = RESERVED_KEYWORDS.get(result, Token('ID', result)) # 如果是保留字返回保留字记号,默认返回ID记号
return token
3、修改get_next_token()方法
因为增加了一些终结符,我们需要在get_next_token()方法中能够返回对应的标记。
示例代码:
def get_next_token(self):
while self.current_char is not None:
...省略部分代码...
if self.current_char.isalpha(): # 如果当前字符是字母
return self._id() # 调用方法返回保留字或赋值名称的记号
if self.current_char == ':' and self.peek() == '=': # 如果当前字符是“:”,并且下一个字符是“=”。
self.advance() # 提取下一个字符
self.advance() # 提取下一个字符
return Token(ASSIGN, ':=') # 返回赋值符的记号
if self.current_char == ';': # 如果当前字符是分号
self.advance() # 提取下一个字符
return Token(SEMI, ';') # 返回分号记号
if self.current_char == '.': # 如果当前字符是点
self.advance() # 提取下一个字符
return Token(DOT, '.') # 返回点记号
...省略部分代码...
return Token(EOF, None)
三、添加新的节点类
复合语句、赋值语句、变量和空语句都要对应的添加节点类。
1、添加复合语句节点类
复合语句本身没有什么内容,它只包含子节点。
示例代码:
class Compound(AST): # 添加复合语句节点
def __init__(self):
self.children = [] # 子节点列表
2、添加赋值语句节点类
赋值语句由左侧的变量、赋值符和右侧的表达式组成。
示例代码:
class Assign(AST): # 添加赋值语句节点
def __init__(self, left, operator, right):
self.left = left # 变量名称
self.token = self.operator = operator # 记号和赋值符号
self.right = right # 右侧表达式
3、添加变量节点类
类似于整数,变量是一个名称。
示例代码:
class Variable(AST): # 添加变量节点
def __init__(self, token):
self.token = token # 记号
self.name = token.value # 变量值
4、添加空语句类
空语句没有任何内容。
示例代码:
class NoOperator(AST): # 添加空语句节点
pass # 无内容
四、添加语法分析器(Parser)中的方法
对应着文法中的每一条规则,需要添加7个方法,用来解析新的语言构造和创建节点对象。
按照包含关系,我们从创建变量节点开始。
1、获取变量节点的方法
示例代码:
def variable(self): # 添加获取变量节点的方法
node = Variable(self.current_token) # 获取变量节点
self.eat(ID) # 验证变量名称
return node # 返回变量节点
2、获取空语句的节点
示例代码:
def empty(self): # 添加获取空语句节点的方法
return NoOperator() # 返回空语句节点
3、获取赋值语句节点代码
示例代码:
def assignment_statement(self): # 添加获取赋值语句节点的方法
left = self.variable() # 获取变量名称节点
token = self.current_token # 获取当前记号
self.eat(ASSIGN) # 验证赋值符
right = self.expr() # 获取表达式节点
node = Assign(left, token, right) # 组成赋值语句节点
return node # 返回赋值语句节点
4、获取语句节点代码
示例代码:
def statement(self): # 添加获取语句节点的方法
if self.current_token.value_type == BEGIN: # 如果遇到BEGIN,说明包含复合语句。
node = self.compound_statement() # 获取复合语句节点
elif self.current_token.value_type == ID: # 如果遇到一个名称,说明是赋值语句。
node = self.assignment_statement() # 获取赋值语句节点
else: # 否则就是空语句
node = self.empty() # 返回空语句节点
return node # 返回语句节点
5、获取语句语句列表节点的方法
示例代码:
def statement_list(self): # 添加获取语句列表节点的方法
node = self.statement() # 获取第一条语句节点
nodes = [node] # 添加第一条语句节点到列表
while self.current_token.value_type == SEMI: # 如果遇到分号
self.eat(SEMI) # 验证分号
nodes.append(self.statement()) # 添加下一条语句节点到列表
if self.current_token.value_type == ID: # 如果只遇到一个名称而非语句
self.error() # 抛出异常
return nodes # 返回语句节点列表
6、获取复合语句节点的方法
示例代码:
def compound_statement(self): # 添加获取复合语句节点的方法
self.eat(BEGIN)
nodes = self.statement_list() # 包含节点为语句列表
self.eat(END)
root = Compound() # 创建复合语句节点对象
# for node in nodes: # 遍历语句列表中的语句节点
# root.children.append(node) # 将语句节点添加到复合语句节点列表
root.children = nodes # 将语句节点列表添作为复合语句节点的子节点列表
return root # 返回复合语句节点对象
7、获取程序中所有节点对象的方法
示例代码:
def program(self): # 添加获取程序所有节点方法
node = self.compound_statement() # 包含节点为复合语句
self.eat(DOT)
return node
除了添加这些新的方法,对于新添加的因子,我们还需要修改factor()方法和parser()方法。
示例代码:
def factor(self):
current_token = self.current_token
if current_token.value_type == PLUS:
...省略部分代码...
else: # 新增变量因子
node = self.variable() # 获取变量节点
return node # 返回变量节点
def parser(self):
node = self.program() # 获取程序所有节点
if self.current_token.value_type != EOF: # 如果当前不是文件末端记号
self.error() # 抛出异常
return node # 返回程序节点
通过上面的添加与修改,语法分析器以及能够正常工作了。
此时的AST结构如下:(转自鲁斯兰的原文,实在懒的画。)
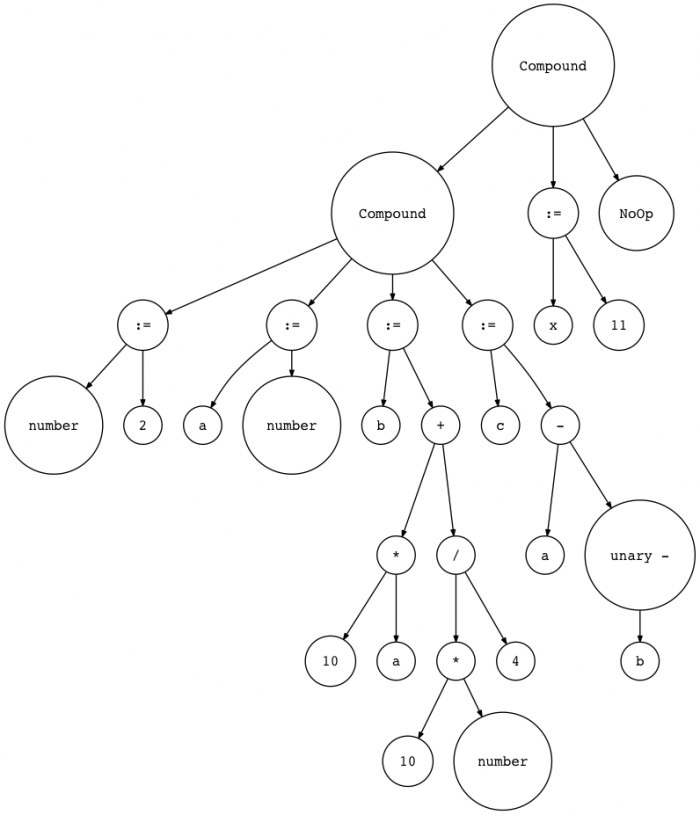
五、添加新的访问方法
为了解释新的AST节点,我们需要向解释器添加相应的访问方法。有四种新的访问方法:
- visit_Compound
- visit_Assign
- visit_Variable
- visit_NoOperator
示例代码:
class Interpreter(NodeVisitor):
GLOBAL_SCOPE = {} # 创建符号表
def __init__(self, parser):
self.parser = parser
def visit_Compound(self, node): # 访问复合语句节点
for child in node.children: # 遍历复合语句节点的子节点
self.visit(child) # 访问子节点
def visit_Assign(self, node): # 访问赋值语句节点
var_name = node.left.name # 获取变量名称
self.GLOBAL_SCOPE[var_name] = self.visit(node.right) # 以变量名称为键添加变量值到符号表
def visit_Variable(self, node): # 访问变量节点
var_name = node.name # 获取变量名称
value = self.GLOBAL_SCOPE.get(var_name) # 获取变量值
if value is None: # 如果没有返回值(变量不存在)
raise NameError(f'错误的标识符:{repr(var_name)}') # 抛出异常
else: # 否则
return value # 返回变量值
def visit_NoOperator(self, node): # 访问空语句节点
pass # 无操作
上方代码中,包含了所有要添加的访问方法,并且添加了详细的注释,大家可以参考理解。
这里有一个新的数据类型–符号表(Symbol Table),也就是代码中的“GLOBAL_SCOPE”。
符号表是一种抽象的数据类型(ADT:abstract data type),用于跟踪源代码中的各种符号。
我们现在唯一的符号类别是变量,我们使用Python字典来实现符号表,保存变量的名称和值。
在鲁斯兰的文章中提到:
在这里中使用符号表的方式很“变态”。因为,这里的符号表不是一个单独的类,并具有特殊的方法,而是一个简单的Python字典,它也作为内存空间执行双重任务。在以后的文章中,我们将更详细地讨论符号表,同时我们也将解决掉程序中存在的问题。
好了,先不管它变不变态,我们来看一下符号表在执行访问方法前后产生的变化。
例如,解释语句“A:=3”:
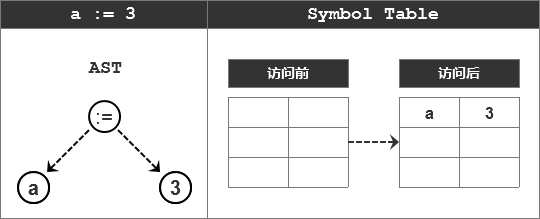
再解释语句“b:= a+7”:
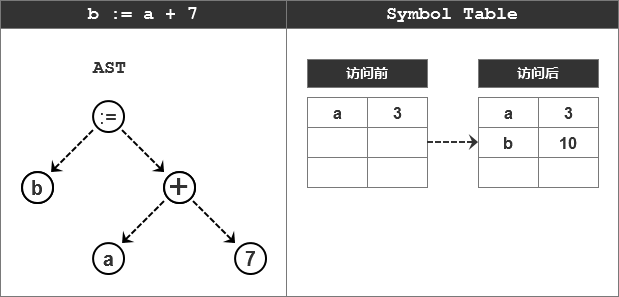
总结一下,在这篇文章中都做了什么样的扩展:
1、文法中添加了新的规则;
2、在词法分析器(Lexer)中添加了新的记号和相应的方法,并更新了get_next_token()方法;
3、添加了新的AST节点类,以构建新的语言结构;
4、在语法分析器(Parser)中对应新的文法规则添加了新的方法,并更新了现有的factor()方法;
5、在解释器(Interpreter)中添加了新的访问方法;
6、添加了一个用于存储和查询变量的字典(符号表)。
接下来,我们修改一下主函数,运行程序将符号表显示出来。
示例代码:
def main():
text = '''
BEGIN
BEGIN
number := 2;
a := number;
b := 10 * a + 10 * number / 4;
c := a - - b;
END;
x := 11;
END.
'''
lexer = Lexer(text)
parser = Parser(lexer)
interpreter = Interpreter(parser)
interpreter.interpret()
print(interpreter.GLOBAL_SCOPE) # 显示输出符号表
以上就是本篇文章的所有内容。
不过,我们的解释器还存在着很多缺陷:
1、程序文法规则不完整,之后我们将用其他元素来扩展它。
2、Pascal是静态语言,声明变量必须指定类型。
3、没有类型检查。
4、当前符号表是一个简单的Python字典,它作为内存空间执行双重任务。
5、在Pascal中,必须使用关键字DIVTO指定整数除法。(当前我们使用双斜杠“//”来表示整数除法)
6、在Pascal中,所有保留关键字和标识符都不区分大小写。
这些缺陷在之后的文章中逐步排除。
最后,是本篇文章的练习内容:
1、Pascal变量和保留关键字不区分大小写,所以“BEGIN”、“begin”和“BeGin”都引用相同的保留关键字。更新解释器,使变量和保留关键字不区分大小写。
2、我们的解释器使用斜杠“/”来表示整数除法,修改解释器,使用“div”关键字进行整数除法。
3、让变量可以使用下划线开头,例如“_num := 5”。
使用下面的程序来测试以上练习:
BEGIN BEGIN number := 2; a := NumBer; B := 10 * a + 10 * NUMBER DIV 4; _c := a - - b end; x := 11; END.
练习源代码下载:【点此下载】
项目源代码下载:【点此下载】
转载请注明:魔力Python » 一起来写个简单的解释器(9)
def visit_Assign(self, node): var_name = node.left.name # 此处修改value为name def visit_Variable(self, node): var_name = node.name # 此处修改value为name